Implementation of Fundemental ML Concepts

From Zero to Hero: Building Machine Learning Models with Karpathy's NN Zero-to-Hero Course
This project showcases my journey through Andrej Karpathy’s renowned NN Zero-to-Hero course, where I progressively built machine learning models of increasing complexity. Each step of the course deepened my understanding of neural networks, guiding me from simple statistical models to implementing concepts from fundemental understandings such as gradient decent to the more recent Transformer architecture.
Progressive Model Development
The course began with fundamental machine learning principles and quickly advanced to constructing increasingly sophisticated models:
-
Bigram Models: These simple statistical models were the starting point, capturing probabilities of sequences of two elements. Bigram models laid the foundation for a statistical understanding predictive modeling.
-
WaveNet-inspired Generative Models: Inspired by WaveNet: A Generative Model for Raw Audio, this step introduced autoregressive models that demonstrated how to generate high-fidelity sequences from raw data.
-
Residual Networks: Leveraging the principles of Deep Residual Learning for Image Recognition, I implemented networks that mitigated vanishing gradients and allowed deeper architectures.
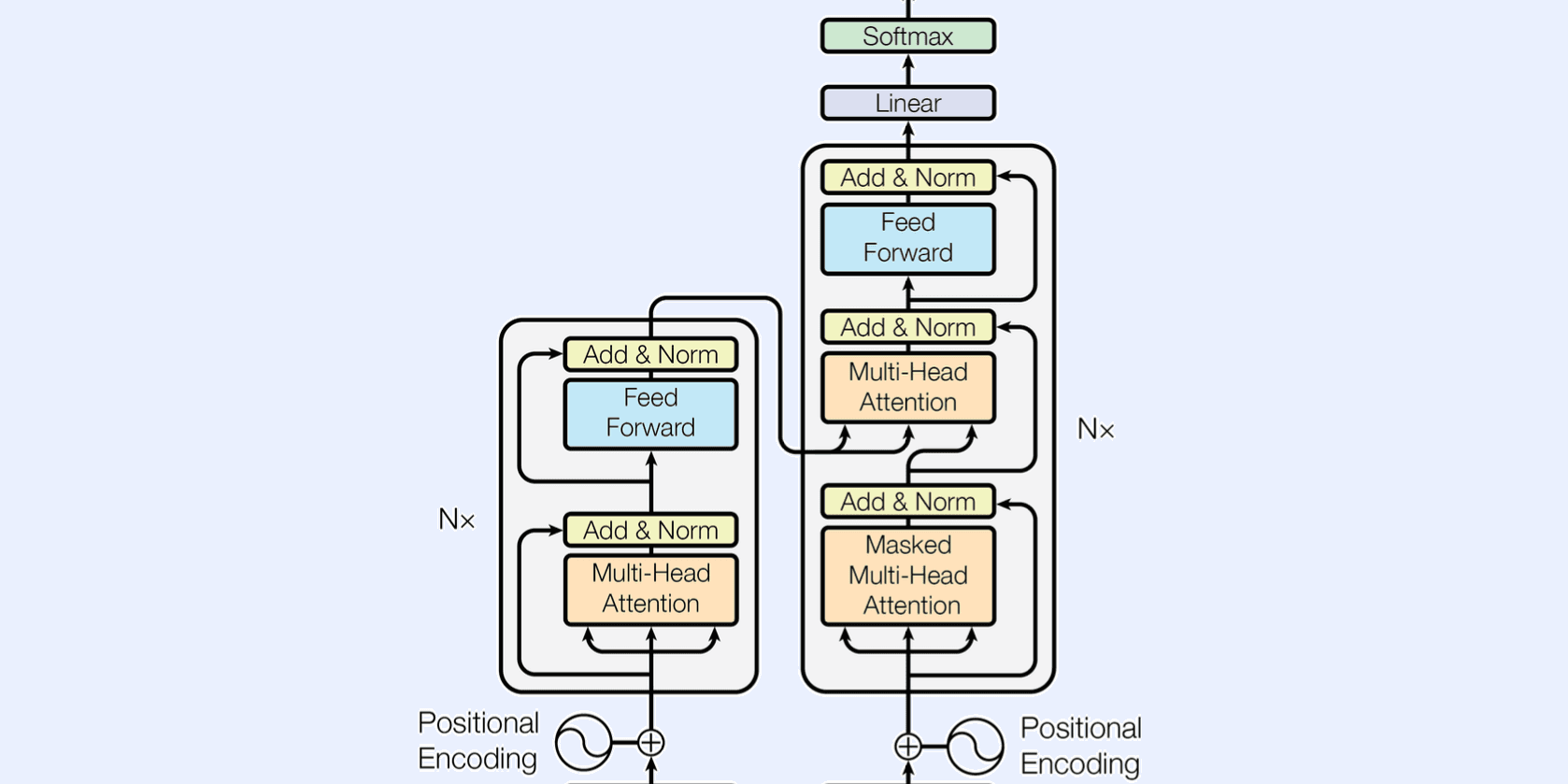
The Culmination: Transformer Models
The pinnacle of the course was the implementation of a basic transformer model, inspired by the revolutionary Attention Is All You Need paper. This section involved:
Basic Transformer module
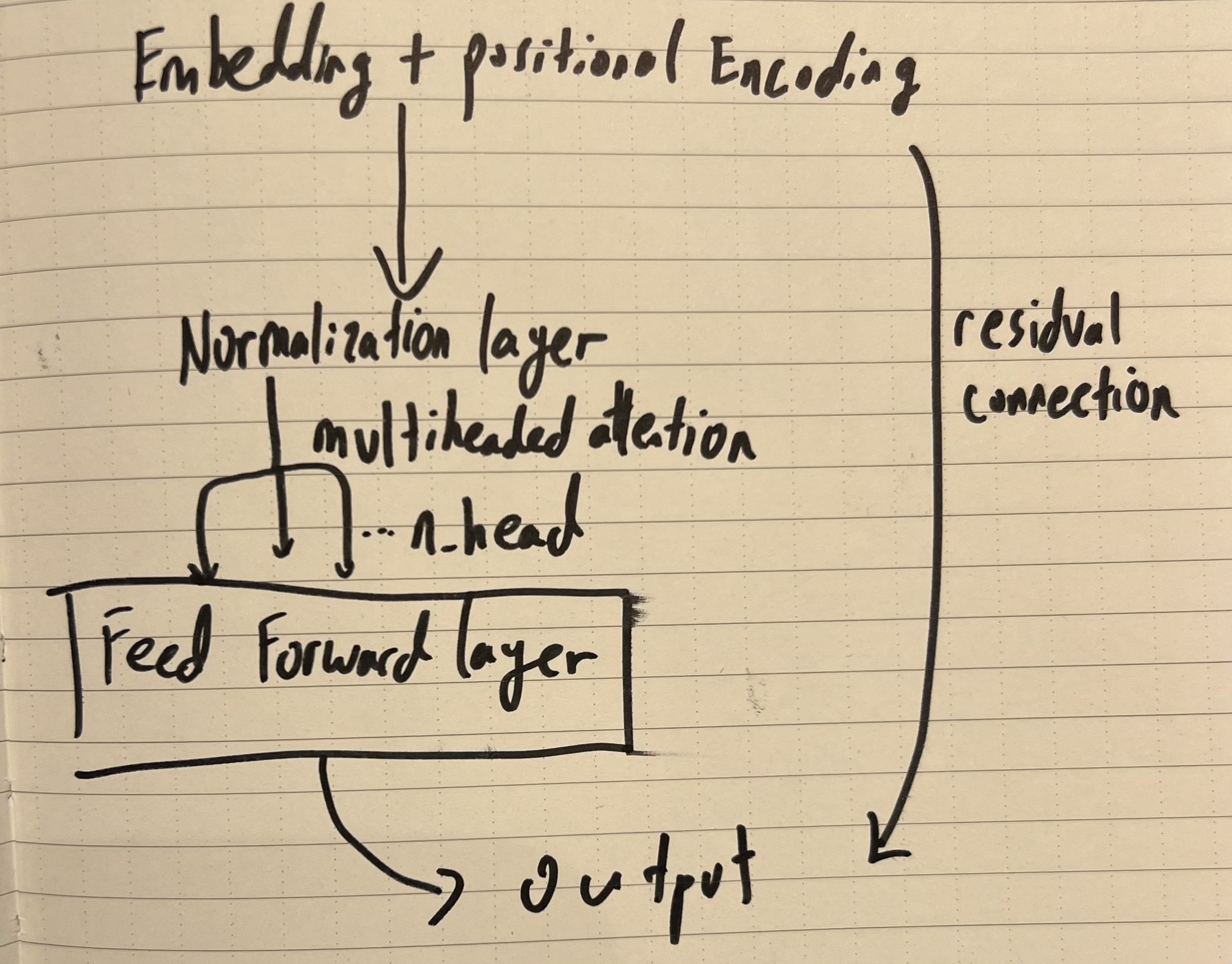
- Self-Attention Mechanisms: Understanding how transformers focus on different parts of an input sequence to encode contextual relationships efficiently.
- Positional Encodings: Implementing positional embeddings to preserve the sequential nature of the data.
- Scalability: Appreciating how transformers serve as a scalable backbone for diverse applications, from natural language processing to computer vision.
How the implementation differs from that in the paper
- Tokenisation: unlike the paper, individual characters were used as tokens instead of subwords or word chunks
- Dropout Layer in the FeedForward layer
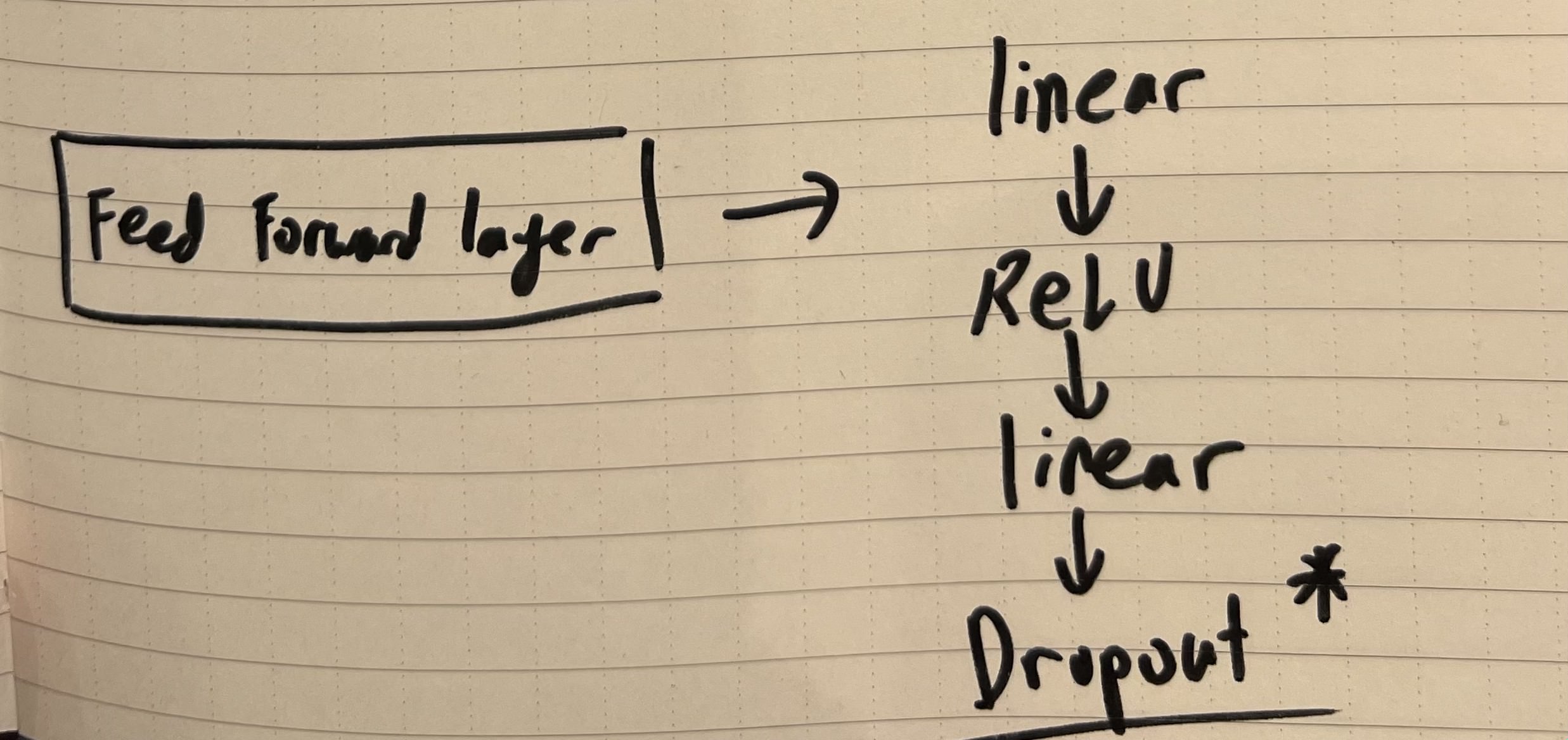 Introduced in the paper titled; Improving neural networks by preventing co-adaptation of feature detectors ML Paper (Dropout Technique); a dropout layer was implemented to reduce overfitting
Introduced in the paper titled; Improving neural networks by preventing co-adaptation of feature detectors ML Paper (Dropout Technique); a dropout layer was implemented to reduce overfitting - Due to the difference in nature of the task, (Attention is all you need was tasked with translation), there was the additional implementation of Cross Attention, which is not possible in my model
Final Deliverable
A Transformer based model trained on the Tiny Shakesphere dataset to produce Shakesphere like language.
Here is a sample of the text produced:
MARIANA:
Basta, desperate of my sword; can I do be voth
To dine in the voice? Or else it hath a drunken two
And dancient now in France was Delphon, Master
A lady's father, and when men must sell him.
DUKE VINCENTIO:
Now miserable complainings
But by whose conjuration can, that show
What fair with cunning which dreams them wear
These one anon.
Model Parameters:
| Component | Details |
|---|---|
| Tokenization | Type: Character-level |
| Vocabulary Size: 65 characters | |
| Embeddings | Token Embedding Dimension: 384 |
| Positional Embedding Dimension: 384 | |
| Model Architecture | Type: Transformer-based Causal Language Model (GPT-like) |
| Number of Transformer Blocks: 6 | |
| Multi-Head Attention: | |
| • Number of Heads: 6 | |
| • Head Size: 64 | |
| Feedforward Network: | |
| • Hidden Dimension: 1,536 (4 × 384) | |
| Dropout Rate: 0.2 | |
| Layer Normalization: Pre-Norm applied before attention and feedforward layers | |
| Parameters | Total Parameters: ~10.789 Million |
| Breakdown: | |
| • Token Embeddings: 24,960 | |
| • Positional Embeddings: 98,304 | |
| • Transformer Blocks: 10,639,872 | |
| • Final LayerNorm: 768 | |
| • Language Modeling Head: 25,025 | |
| Training Setup | Batch Size: 64 |
| Context Length (Block Size): 256 tokens | |
| Maximum Iterations: 5,000 | |
| Evaluation Interval: Every 500 iterations | |
| Learning Rate: 3e-4 | |
| Optimizer: AdamW | |
| Loss Function: Cross-Entropy | |
| Training/Validation Split: 90% training, 10% validation | |
| Evaluation Batches: 200 per split | |
| Device Configuration | Primary Device: CUDA (GPU) if available, otherwise CPU |
| CUDA Details: Automatically detects and utilizes the first CUDA device available | |
| Data Handling | Dataset: input.txt (e.g., "tinyshakespeare") |
Encoding: String to Integer indices (stoi mapping) | |
Decoding: Integer indices to String (itos mapping) | |
| Batch Generation: Random sampling of sequences with a maximum length of 256 tokens | |
| Generation Features | Method: Sequential token generation using softmax probabilities and multinomial sampling |
| Maximum New Tokens: Configurable (e.g., 500 or 10,000 tokens) | |
| Context Handling: Maintains a rolling window of the last 256 tokens to respect context limit | |
| Weight Initialization | Linear Layers: Initialized with Normal Distribution (mean=0.0, std=0.02), Bias=0 |
| Embedding Layers: Initialized with Normal Distribution (mean=0.0, std=0.02) | |
| Regularization Techniques | Dropout: Applied to attention weights and feedforward networks (rate=0.2) |
| Progress Tracking | Tool: tqdm for real-time monitoring of training progress and loss metrics |
| Post-Training Outputs | Loss Plots: Saved as training_plot.png |
Model Saving: State dictionary saved as microGPT_model.pth |
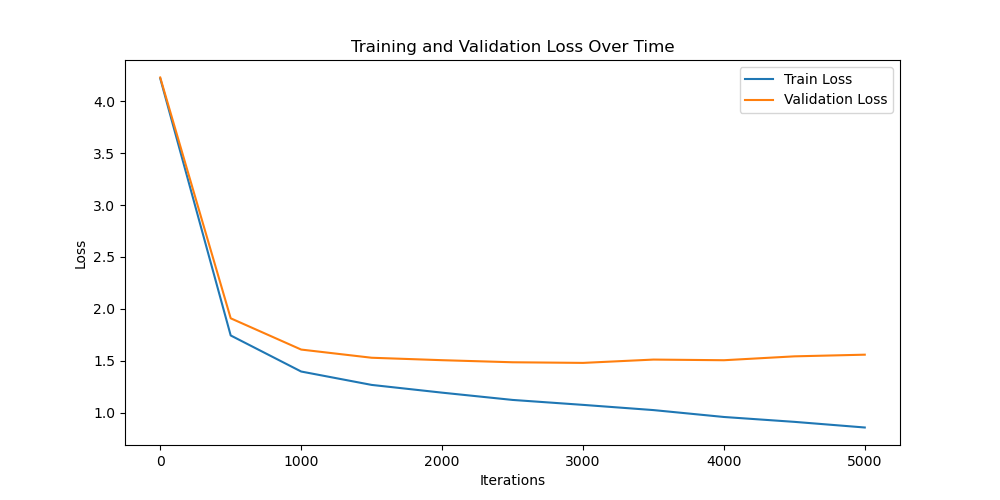
Training Results with CUDA on a RTX2070
Explore the Code
Dive into the technical implementation and explore the project repository: GitHub Repository: Machine Learning Learning